
Vanuit beleggers is er de wens om snel te kunnen inspelen op ontwikkelingen in een bedrijf. Sneller dan zou kunnen op basis van het door accountants goedgekeurde jaarverslag. Doordat de ontwikkelingen op het gebied van kunstmatige intelligentie elkaar snel opvolgen ontstaan er meer mogelijkheden hiervoor. Door gebruik te maken van de modernste technieken voor het begrijpen van tekst tonen wij aan dat het mogelijk is om de omzetgroei van bedrijven en daarmee aandelenrendementen beter te voorspellen. Inmiddels zijn we zo ver dat deze vorm van geautomatiseerd tekstbegrip een plaats heeft gekregen in het samenstellen van een aandelenportefeuille. Ook zijn er in de laatste decennia verdere ontwikkelingen geweest in de verbetering en internationale convergentie van accountingstandaarden. Deze maken het beter mogelijk omzetcijfers te vergelijken en te interpreteren.
In dit artikel gaan we in op de resultaten van ons onderzoek waarbij we eerst laten zien dat omzetgroei voorspellende waarde heeft voor de ontwikkeling van aandelenkoersen. Vervolgens worden technieken om geautomatiseerd tekst te begrijpen nader toegelicht. Onze bevinding is dat deze nieuwe technieken voor tekstbegrip gebruikt kunnen worden om voorspellingen van de omzetgroei van bedrijven aanzienlijk te verbeteren. Tot slot wordt verder ingegaan op hoe deze verbeterde voorspellingen van omzetgroei gebuikt worden bij het samenstellen van een aandelenportefeuille. Deze nieuwe informatiebron genereert voor een doorsnee aandelenfonds tussen de 0,25% en 0,50% extra rendement.
 OMZETGROEI IS EEN VOORSPELLER VAN AANDELENRENDEMENTEN
OMZETGROEI IS EEN VOORSPELLER VAN AANDELENRENDEMENTEN
In de laatste decennia zijn internationale standaarden op het gebied van accounting verbeterd; standaarden met betrekking tot het erkennen van omzetgroei zijn verder geconvergeerd; tot slot is het elektronisch publiceren van kwartaal- en jaarcijfers en verslagen gemeengoed geworden. In de Verenigde Staten worden kwartaal- en jaarverslagen inmiddels sinds 1994 elektronisch gepubliceerd. Nu kwalitatief verbeterde omzetcijfers beschikbaar zijn dient de vraag zich aan: beïnvloed de omzetgroei van een bedrijf zijn beurskoers? Zo ja, hoe? Het idee hierachter is simpel; als omzetgroei van invloed is op aandelenkoersen, dan zou het lonen om deze te kunnen voorspellen. Als dit niet het geval is, dan heeft het voorspellen van omzetgroei ook geen toegevoegde waarde. Wanneer in dit artikel over omzetgroei gesproken wordt, dan gaat dit over de jaar-op-jaar groei van de omzet die de afgelopen twaalf maanden gerealiseerd is. Deze keuze voor jaar-op-jaar groei is gemaakt om seizoensinvloeden in de cijfers uit te sluiten.
Omzetgroei gerelateerde maatstaven
Omzetgroei is de procentuele groei van de gerealiseerde omzet over de afgelopen 12 maanden ten opzichte van de voorgaande 12 maanden
Omzetgroeiversnelling is het verschil tussen de omzetgroei van het laatste kwartaal ten opzichte van het voorgaande kwartaal
Omzetgroeiverrassing is het verschil tussen de huidige omzetgroei en de geëxtrapoleerde omzetgroei op basis van de cijfers tot en met vorig kwartaal.
Om de eerste vraag te beantwoorden wordt de Informatiecoëfficiënt (IC) (Grinold, 1989) van omzetgroei berekend. Dit is gedaan voor bedrijven die opgenomen zijn in de MSCI World. De IC is de correlatie tussen omzetgroei en het aandelenrendement over het opvolgende kwartaal. Als de IC verschilt van 0 betekent het dat aandelenrendementen voorspeld kunnen worden aan de hand van omzetgroei. Deze correlatie wordt berekend per sector. Dit wordt zo gedaan vanwege twee redenen.
Ten eerste omdat de groeicijfers tussen sectoren aanzienlijk verschillen. Groei van technologiebedrijven is bijvoorbeeld intrinsiek anders dan groei van nutsbedrijven. Het is wenselijk dat de uitkomsten niet door dergelijke eigenschappen van sectoren verstoord worden. Ten tweede is de verwachting dat de aandelenkoersen van bedrijven in sectoren met lage variabele kosten (zoals bijvoorbeeld de software- industrie) fors reageren op veranderingen in omzetgroei. Voor sectoren met hoge variabele kosten (zoals bijvoorbeeld bij restaurantketens) is de verwachting juist een meer gematigde reactie. Door de unieke eigenschappen van sectoren in acht te nemen in de berekeningen, kan worden vastgesteld of er inderdaad verschillen tussen sectoren zijn. Om toch een algeheel beeld te krijgen worden tot slot de sector IC’s geaggregeerd tot een gemiddelde over alle sectoren. In het totaal gaat het dan om ongeveer 40000 waarnemingen in de periode 2011 – 2021. De resultaten zijn weergegeven in tabel 1.
Infomatiecoëfficient
De informatiecoefficiënt (IC) is een maatstaf die de vaardigheid aangeeft om rendementen te voorspellen.
In de praktijk liggen IC’s tussen de 0% en 10%. Om intuïtie te krijgen bij de waarde van een IC, kan deze vertaald worden naar de vaardigheid van het voorspellen van kop of munt.
Een IC van 6% zou een vaardigheid betekenen om gemiddeld 53 van de 100 keer juist kop of munt te voorspellen. Een IC van 0% betekent geen vaardigheid. Dan wordt dus gemiddeld 50 van de 100 keer kop of munt juist voorspeld.
De eerste bevinding is dat voorkennis van omzetgroei een IC heeft van 4,7%. Dat is omvangrijk en biedt perspectief voor een strategie gebaseerd op omzetgroei.
De vervolgvraag die we kunnen stellen is wat dit verband verklaart. De omzetgroei van bedrijven blijkt behoorlijk aanhoudend te zijn (zie tabel 2). Als bedrijven op basis van hun huidige omzetgroei worden gerangschikt, dan is deze rangschikking het volgend kwartaal voor 60% hetzelfde. Uit deze observatie is het idee voortgekomen om te kijken of het de verrassing in omzetgroei is die aandelenkoersen beweegt.
Er zijn verschillende mogelijkheden om deze verrassing te bepalen, zoals de mate waarin omzetgroei afwijkt:
- van wat analisten verwachten, of
- van de omzetgroei bij de vorige rapportage (omzetgroeiversnelling), of
- van een regressie op de laatst gerapporteerde omzetgroei (omzetgroeiverrassing).
Er is voor dat laatste mogelijkheid gekozen. De verwachtingen van analisten kunnen tussentijds aangepast worden en zijn niet voor alle bedrijven beschikbaar, dus deze mogelijkheid is minder geschikt. De reden om niet te kiezen voor de omzetgroeiversnelling is omdat groeicijfers de neiging hebben naar hun gemiddelde terug te keren.
De omzetgroeiverrassing laat een IC van 6,2% zien. Dat is een aanzienlijke toename ten opzichte van de 4,7% voor omzetgroei. Daarom zal het onderzoek zich verder richten op het voorspellen van omzetgroeiverrassing.
Tabel 3 laat de omzetgroeiverrassing IC zien voor de top 5 sectoren in omvang binnen de MSCI World. De IC van de Software en Services is zelfs 11,9%. Omdat dit meteen een grote sector betreft (12% van MSCI World) is hier in het onderzoek prioriteit aan gegeven.
Nu vastgesteld is dat het loont om de verrassing in omzetgroei goed te kunnen voorspellen, wordt nader bekeken welke methoden daarvoor beschikbaar zijn.
ER ZIJN VERSCHILLENDE METHODEN OM OMZETGROEI TE VOORSPELLEN
Eén van de meest traditionele methoden is om gebruik te maken van analisten. Bij het zelf doen van analyses is het lastig om het volledig universum op een consistente manier te voorspellen. Een analist volgt doorgaans tussen de 30 en 50 bedrijven en de gehele software en services sector is al omvangrijker. Dan zijn er meerdere analisten nodig die niet altijd op een consistente wijze te werk gaan.
Een alternatief is om gebruik te maken van gemiddelden van sell-side analisten. Hierdoor worden de schattingen beter vergelijkbaar. Eventueel kan ervoor gekozen worden om analisten met een goed trackrecord een groter gewicht te geven. In dat geval zal het gewogen gemiddelde nog beter voorspellend zijn. Over de afgelopen 10 jaar hebben we een 30% correlatie gemeten tussen de koersontwikkeling van bedrijven en aanpassingen van omzetverwachtingen van analisten. Bij een gunstige koersontwikkeling worden dan gunstige omzet en winstcijfers voorspeld. Dat vinden we voor dit onderzoek onwenselijk omdat we juist op zoek zijn naar de verrassing.
Een manier die de laatste jaren in opkomst is om de omzetgroei te voorspellen, is door gebruik te maken van transactiedata. Voor bepaalde sectoren en landen is geaggregeerde transactiedata te koop. Te denken valt aan consumententransacties of ziektekostendeclaraties. Dergelijke data worden vergaard via bedrijven die transacties verwerken, via loyalty programma’s of verkregen van zorgverzekeraars. In verschillende regio’s en landen gelden verschillende regels voor gegevensbescherming. Hierdoor zal de transactiedata nooit de gehele markt kunnen dekken. Voor restaurants en medicijngebruik zijn er bijvoorbeeld in de Verenigde Staten zeer representatieve datasets.
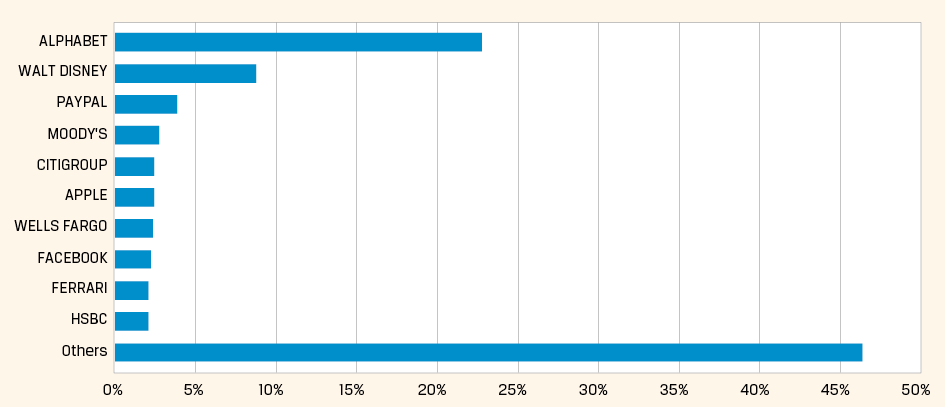
Eerder onderzoek heeft vastgesteld dat 80% van de relevante data in ongestructureerde (tekst)vorm beschikbaar is (Bhattacharya et al., 2021). Dat is een aanzienlijke alternatieve bron van data. De methode die in dit artikel beschreven wordt maakt dan ook gebruik van tekst. Er is voor gekozen om vanuit uitspraken van het management van een bedrijf omzetgroei te voorspellen. De gedachte hierachter is dat de communicatie van een bedrijf indicatief is voor de toekomst. Te denken valt aan uitspraken over de uitbreiding of het terugschroeven van productiecapaciteit, of het aannemen van personeel, etc. Voor de keuze van de data is er in eerste instantie gezocht naar een dataset die zo consistent mogelijk is en een even grote dekking geeft voor bedrijven, ongeacht hun omvang. Het vinden van een tekstbron die een gelijkmatige dekking geeft over bedrijven is nog niet zo eenvoudig. Uit figuur 1 wordt duidelijk dat meer dan 50% van alle artikelen in het financiële nieuws en de sociale media zich slechts met tien bedrijven bezighouden. De gelijkmatige dekking is van belang omdat bij een scheve verdeling in de dekking deep learning modellen de neiging hebben om slechter te generaliseren. De uiteindelijke keuze is gevallen op de managementdiscussie die bedrijven in de Verenigde Staten verplicht registreren bij de SEC als onderdeel van hun kwartaalof jaarrapportage. De zogenaamde ‘SEC-filings’ worden sinds 1994 elektronisch aangeleverd, zodat er ook voldoende historie is om onze methode mee te testen. Aangezien elk bedrijf per kwartaal één keer rapporteert is de dekking precies gelijk. Een bijkomend argument om de data te beperken tot de Verenigde Staten is dat resultaten dan niet negatief beïnvloed worden door verschillen in accountingstandaarden.
DE ONTWIKKELING VAN NATURAL LANGUAGE PROCESSING TECHNIEKEN
Het geautomatiseerd verwerken van tekst (Natural Language Processing, kortweg NLP) behoort inmiddels tot een gangbare techniek binnen vermogensbeheer. De eerste NLP-methoden werkten met vaste regels die onderzoekers zelf definieerden. Hedendaagse modellen leren daarentegen hun taalkundig begrip grotendeels zelfstandig uit tekstdata met minder en minder voorgeschreven regels of preconcepties over hoe taal hoort te werken. Deze evolutie van NLP is goed te omschrijven aan de hand van de drie hoofdtype NLP-methodes die elkaar logischerwijs opgevolgd hebben.
 Allereest is er statistische NLP. Bij statistische NLP wordt tekst samengevat in een aantal statistische attributen. Bijvoorbeeld de frequentie waarmee bepaalde woorden voorkomen. Aan de hand van deze attributen kunnen voorspellingen gedaan worden, bijvoorbeeld van sentiment. Het tweede type NLP-modellen maakt gebruik van neurale netwerken in combinatie met zogenaamde “word embeddings”. Word embeddings zetten woorden om in vectoren van getallen. Woorden die ongeveer hetzelfde betekenen hebben ongeveer dezelfde numerieke waarden. De vectoren kunnen bij elkaar worden opgeteld en afgetrokken, waarbij de uitkomst taalkundig logisch is. Bijvoorbeeld in vectoren zou de uitkomst van “koning – man + vrouw” “koningin” zijn. De meest recente stap in de evolutie van NLP-technieken is de introductie van grote neurale netwerken die vooraf getraind zijn op een enorme hoeveelheid tekst van diverse bronnen. Dit leidt tot een sterke verbetering ten opzichte van traditionele Word Embeddings doordat de woordrepresentaties contextbewust zijn. Voor de specifiekere taken en kleinere datasets die men in praktische applicaties dikwijls tegenkomt worden deze modellen vaak kort verder bijgetraind.
Allereest is er statistische NLP. Bij statistische NLP wordt tekst samengevat in een aantal statistische attributen. Bijvoorbeeld de frequentie waarmee bepaalde woorden voorkomen. Aan de hand van deze attributen kunnen voorspellingen gedaan worden, bijvoorbeeld van sentiment. Het tweede type NLP-modellen maakt gebruik van neurale netwerken in combinatie met zogenaamde “word embeddings”. Word embeddings zetten woorden om in vectoren van getallen. Woorden die ongeveer hetzelfde betekenen hebben ongeveer dezelfde numerieke waarden. De vectoren kunnen bij elkaar worden opgeteld en afgetrokken, waarbij de uitkomst taalkundig logisch is. Bijvoorbeeld in vectoren zou de uitkomst van “koning – man + vrouw” “koningin” zijn. De meest recente stap in de evolutie van NLP-technieken is de introductie van grote neurale netwerken die vooraf getraind zijn op een enorme hoeveelheid tekst van diverse bronnen. Dit leidt tot een sterke verbetering ten opzichte van traditionele Word Embeddings doordat de woordrepresentaties contextbewust zijn. Voor de specifiekere taken en kleinere datasets die men in praktische applicaties dikwijls tegenkomt worden deze modellen vaak kort verder bijgetraind.
Het meest bekende voorbeeld van dit soort neurale netwerken is BERT (Bidirectional Encoder Representation from Transformers) (Devlin et al., 2019). BERT verwerkt 512 woorddelen in één keer en vertaalt dat naar vectoren. BERT is ontwikkeld door Google en is momenteel één van de beste modellen als het gaat om taken waarbij taalbegrip van belang is. Eén van deze taken is het voorspellen van de volgende zin die iemand zal zeggen of schrijven. Er bestaan varianten van BERT die getraind zijn voor specifieke soorten tekst. Zo is er FinBERT (Araci, 2019) dat specifiek getraind is voor het verwerken van taal die binnen financiële instellingen gebruikt wordt. Een andere variant is RoBERTa (Liu et al., 2019), welke op 10 keer zo veel tekst is getraind in vergelijking met BERT en een meer robuuste methodiek gebruikt voor het trainen van het model. De extra tekst komt van algemeen nieuws en andere van internet afkomstige tekstbronnen.
NATURAL LANGUAGE PROCESSING IN DE PRAKTIJK
Zoals eerder opgemerkt is in het onderzoek prioriteit gegeven aan de Software en Services sector in de Verenigde Staten. Vanaf 1994 is bepaald welke beursgenoteerde bedrijven in deze sector actief waren. Van elk van deze bedrijven zijn de historische SEC filings gedownload. Vervolgens is uit elke rapportage de managementdiscussie gehaald en de verrassing in omzetgroei in het daaropvolgend kwartaal bepaald. Met deze managementdiscussies en omzetgroeiverrassingen zijn verschillende deep learning modellen getraind.
De data is opgedeeld in een trainingset, een validatieset en een testset. De trainingset wordt gebruikt om modellen te trainen, hiertoe is de data uit de periode 1994 tot en met 2002 gebruikt. De validatieset wordt gebruikt om te kijken hoe de verschillende modellen generaliseren en om het beste model te selecteren. Voor de validatie hebben we de data van 2003 tot en met 2007 gebruikt. Tot slot wordt het uiteindelijk geselecteerde model nog een keer getest op data die nog niet eerder gezien is. Dit om te verifiëren dat de uiteindelijke modelkeuze goed generaliseert. Voor de test gebruiken we data van 2008 tot en met 1 juli 2021. Zowel bij de validatie- als bij de testperiode wordt gewerkt met een rollend schema. Na elk jaar worden de modellen opnieuw getraind met het jaar aan extra data. Bij traditioneel econometrisch onderzoek wordt de data in het algemeen opgedeeld in ‘in-sample’ en ‘out-of-sample’ data. In de machine learning methoden komt de trainingsdata overeen met de ‘in-sample’, maar wordt de ‘out-of-sample’ data nog een keer opgesplitst in validatie en test data. Daarbij kan de validatiedata gebruikt worden om bepaalde modelkeuzes te maken, dit wordt ‘hyper-parameter-tuning’ genoemd.
In het trainen, valideren en testen is het van belang vooraf evaluatiecriteria vast te leggen. In dit geval zijn dat er twee. Allereerst wordt geëvalueerd hoe goed het model bedrijven weet te rangschikken op basis van de verrassing in omzetgroei. Er is gekozen voor een rangschikking omdat uiteindelijk de beste bedrijven in de aandelenportefeuille moeten komen. Daarnaast is rangschikking een robuustere maatstaf dan traditionele criteria zoals de gemiddelde kwadratische fout.
Het tweede criterium is meer kwalitatief. Er wordt een analyse gemaakt van het belang van verschillende inputs in de uiteindelijke voorspelling. Het relatieve belang van de verschillende inputs dient plausibel te zijn. Verderop in dit artikel wordt daar dieper op in gegaan.
Er is geëxperimenteerd op de trainingset met verschillende modellen: RoBERTa en FinBERT. De deep learning modellen hebben nog een laatste lineaire netwerklaag gekregen die de uitkomst samenvat in een voorspellende score. Er is besloten te focussen op verschillende methoden met FinBERT. Ter validatie zijn sommige experimenten herhaald met RoBERTa.
Voor het gehele model is de rangschikking van bedrijven het selectiecriterium. Het model wordt getraind op stukken tekst betreffende individuele bedrijven. Voor die training wordt een loss-functie gekozen die geminimaliseerd wordt. De validatie data set wordt gebruikt om te bepalen met welke loss-functie de beste voorspelling van de rangschikking wordt bereikt. De loss-functie die speciaal voor soortgelijke rangschikkingsproblemen is ontwikkeld, CORAL (COnsistent RAnk Logits) (Cao, et al., 2019) gaf het beste resultaat op de validatieset. Er is dan ook voor CORAL gekozen als loss-functie.
De data is gesplitst in een training-, validatie- en testset. FinBERT is geselecteerd als pre-trained NLP-model en de loss-functie voor de training is gekozen. Hierna moet het model en trainingsopzet geanalyseerd worden.
EEN GOED ONTWERP VAN DEEP LEARNING MODELLEN IS NOODZAKELIJK
 Deep Learning modellen zijn erg flexibel en daardoor in staat om complexe, niet-lineaire verbanden te leggen. Echter door die hoge mate van flexibiliteit zijn ze ook ontvankelijker dan andere modellen voor het onbedoeld aanleren van eenvoudige verbanden die wel aanwezig zijn in de trainingsdata, maar niet optreden buiten de trainingsdata. In het geval van het trainen op omzetgroei zou het bijvoorbeeld zo kunnen zijn dat wordt aangeleerd bij welk bedrijf welke omzetgroei hoort.
Deep Learning modellen zijn erg flexibel en daardoor in staat om complexe, niet-lineaire verbanden te leggen. Echter door die hoge mate van flexibiliteit zijn ze ook ontvankelijker dan andere modellen voor het onbedoeld aanleren van eenvoudige verbanden die wel aanwezig zijn in de trainingsdata, maar niet optreden buiten de trainingsdata. In het geval van het trainen op omzetgroei zou het bijvoorbeeld zo kunnen zijn dat wordt aangeleerd bij welk bedrijf welke omzetgroei hoort.
Om het aanleren van niet-generaliserende verbanden te voorkomen is het noodzakelijk om het model en de trainingsopzet goed te ontwerpen. Er is een aantal principes gevolgd in het ontwerp van het model en de trainingsopzet:
- Ten eerste is tijdens de training geanalyseerd welke stukken tekst het meest bijdragen aan voorspellingen.5,6 Op die manier is nagegaan of het plausibel is dat het model generaliseert. Een veel voorkomend probleem is dat een model veel belang hecht aan tijdsgebonden uitspraken. Denk dan bijvoorbeeld aan tekst gerelateerd aan een specifieke gebeurtenissen zoals de uitbarsting van de IJslandse vulkaan in 2010. Dit vormt een probleem omdat deze gebeurtenis zo specifiek is dat het onwaarschijnlijk is dat het naar de toekomst generaliseert.
- Ten tweede is getest in welke mate een model in staat is bepaalde (ongewenste) eenvoudige verbanden te leggen. In het geval van managementdiscussies is getest hoe goed het model op basis van de gebruikte tekst kan bepalen bij welk bedrijf de managementdiscussie hoort. Het blijkt dat een model in meer dan 80% van de gevallen correct kan identificeren welk bedrijf een managementdiscussie geschreven heeft.
- Tot slot is de training zo ingericht dat zo min mogelijk voordeel te halen is uit het leren van eenvoudige verbanden. Door op een rangschikking te sturen in plaats van absolute cijfers wordt bijvoorbeeld heel veel tijdsafhankelijkheid weggehaald. En door op de verrassing in omzetgroei te trainen wordt geen profijt meer behaald uit het herkennen van welk bedrijf de managementdiscussie heeft geschreven.
AANGETOOND VERBAND TUSSEN VOORSPELLENDE EN GEREALISEERDE OMZETGROEIVERASSINGEN
Na de training en de validatie wordt het model uiteindelijk getest. Er is gekozen voor een model waarin FinBERT wordt bijgetraind op de managementdiscussies. De vectoren die uit FinBERT komen worden geoptimaliseerd om de rangschikking van de verrassing in omzetgroei te voorspellen. Bij de test wordt het model elk jaar weer bijgetraind. Dit heeft tot gevolg dat in de loop van de test meer data beschikbaar komt en we verwachten dan ook een geleidelijk beter wordend model.
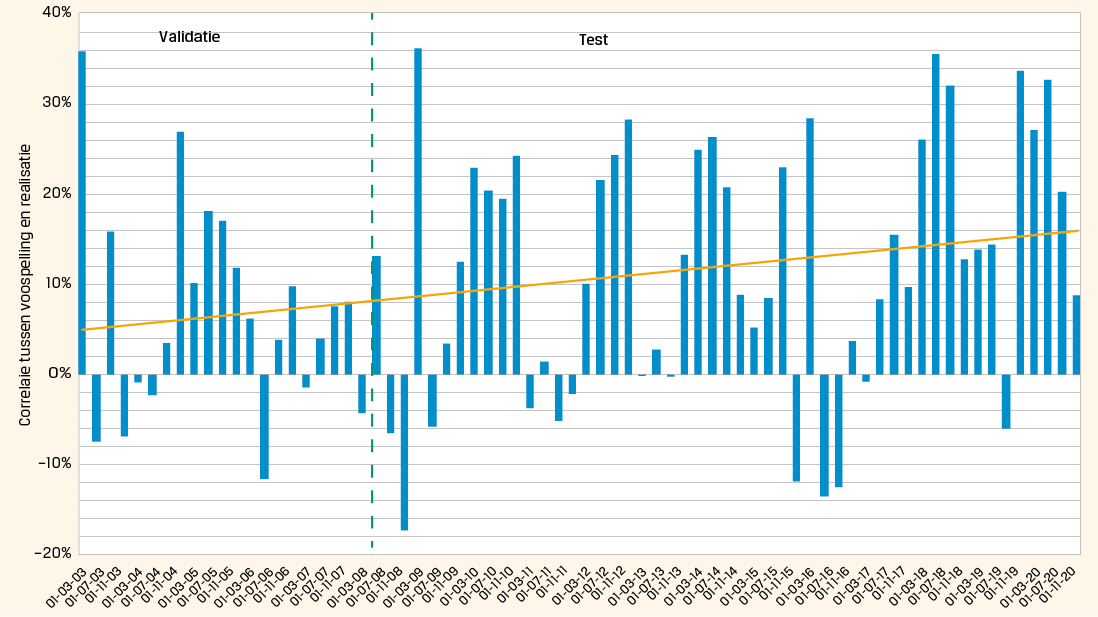
Tabel 4 laat de resultaten zien. We vergelijken de performance van het FinBERT model over de validatieperiode en de testperiode. De performance wordt gemeten als de Spearman Correlatie (rangcorrelatie) tussen voorspelde omzetgroeiverrassing en gerealiseerde omzetgroeiverrassing. Er is te zien dat het model het inderdaad beter doet in de testperiode dan in de validatieperiode. Met een gemiddelde correlatie van 11.6% in de testperiode presteert het model ronduit goed. In de validatie periode hebben we ook een vergelijkbare test gedaan met RoBERTa. Het valt op dat FinBERT aanzienlijk beter presteert. De verklaring daarvoor is dat FinBERT specifiek op financiële teksten is getraind.
In figuur 2 wordt getoond hoe de resultaten er van kwartaal tot kwartaal uitzien. Wat opvalt is dat de gevonden rangcorrelatie tussen voorspelde omzetgroeiverrassing en gerealiseerde omzetgroeiverrassing met het verstrijken van de tijd verbetert en dat er geen grote negatieve uitschieters te zien zijn. Dit geeft aan dat het model goed generaliseert en dat het beter wordt naarmate er meer tekst beschikbaar komt.
GEBRUIK VAN NLP-TECHNIEKEN BIJ HERBALANCERING AANDELENPORTEFEUILLE
Er is nu een nieuwe informatiebron op basis van SEC filings: de rangschikking van omzetgroeiverrassing. Deze informatie komt eerder en regelmatiger binnen dan het door de accountant gecontroleerde jaarverslag. Hoe kan deze informatie het beste in de portefeuille gebruikt worden? Aangezien de informatie een rangschikking betreft binnen een sector heeft de informatie de meeste toegevoegde waarde in het selecteren van aandelen binnen de sector. Het sectorgewicht binnen de portefeuille blijft dus ongewijzigd. Op het moment dat een bedrijf zijn resultaten bekend maakt en dus ook zijn managementdiscussie publiceert, wordt deze verwerkt tot een score. Een hoge score betekent een grote kans op een relatief positieve verrassing in omzetgroei. Deze score wordt vervolgens omgezet in een verwacht rendement op het aandeel in het bedrijf. Het verwachtte rendement op basis van omzetgroeiverrassing wordt gecombineerd met de verwachte rendementen op basis van andere informatie. Met al deze informatie wordt dagelijks een nieuwe modelportefeuille berekend. De modelportefeuille wordt voor twee doeleinden gebruikt. Ten eerste als doelportefeuille om naar toe te sturen als er geld belegd of vrijgemaakt moet worden. Ten tweede om de portefeuille te herbalanceren als de afweging tussen rendement, risico en kosten gunstig is. De publicatie van resultaten vindt doorgaans in een periode van twee tot drie weken plaats. Gedurende deze weken wordt het dan op basis van de nieuw vrijgekomen informatie gunstiger om te herbalanceren. Bedrijven maken op voorhand bekend wanneer ze gaan publiceren en zodra genoeg bedrijven gepubliceerd hebben, wordt de portefeuille geherbalanceerd. Een historische analyse heeft uitgewezen dat voor een doorsnee actief beheerd aandelenfonds deze nieuwe informatiebron jaarlijks tussen de 0,25% en 0,50% extra performance oplevert.7 Dit is bij een turn-over van tussen de 30% en 60%. In de analyse zijn de gebruikelijke restricties, zoals UCITS regels en geen short-selling meegenomen. Er is van uitgegaan dat er eens per kwartaal wordt geherbalanceerd en een schatting van transactiekosten is in mindering gebracht op het resultaat. Dit extra rendement komt bovenop het gebruik van andere beschikbare informatie.
CONCLUSIE
Met behulp van de meest vooraanstaande NLP-technieken zijn we in staat om betere voorspellingen te maken van omzetgroei. Het gebruik van dergelijke technieken vereist specifieke kennis en een goed ontwerp van deep learning modellen is onmisbaar. Deze nieuwe informatiebron wordt vertaald in verwachte rendementen. Op basis van die rendementen wordt de aandelenportefeuille geherbalanceerd. Dit levert voor een doorsnee aandelenfonds tussen de 0,25% en 0,50% extra rendement op. We zien dat accountingstandaarden en rapportages verbeteren en internationaal convergeren. Des te beter en consistenter de kwaliteit van rapportages is, des te groter de kans van succes zal zijn in het voorspellen van omzet. Doordat accountingstandaarden en rapportages internationaal convergeren kunnen NLP-technieken in de toekomst nog breder ingezet worden om omzetgroei te voorspellen.
Literatuurlijst
- Araci, D., 2019 FinBERT: Financial Sentiment Analysis with Pre-trained Language Models arXiv preprint arXiv:1908.10063.
- Bhattacharya, P., Reinders, S., Lanchenko, A., Janssen, L., Braadhaart, J., 2021 Natural language processing: Translating the 80% blind spot Artikel op: https://www.nnip.com/nl-NL/professional/insights/ specials/natural-language-processing-translating-the-80-percent-blind-spot
- Cao, W., Mirjalili, V., & Raschka, S., 2020, Rank consistent ordinal regression for neural networks with application to age estimation. Pattern Recognition Letters, vol. 140, pages 325-331.
- Grinold, R., 1989, The Fundamental law of Active Management. Journal of Portfolio Management, vol. 15, no. 3, pages 30-37.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K., 2019, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT, pages 4171–4186, Minneapolis, Minnesota.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. en Stoyanov, V., 2019. Roberta: A robustly optimized bert pretraining approach arXiv preprint arXiv:1907.11692.
Noten
- De auteurs danken Daan van Everdingen, Renée Schellekens, Jacob van Gelder, Rani Piputri, Judit van der Geest, Jaco Rouw, Siu-Kee Chan en de reviewers van het VBA Journaal voor hun suggesties om dit artikel te verbeteren.
- De kans op een juiste voorspelling van kop of munt als functie van IC is: IC + (1-IC)/2.
- Het model waaruit de omzetgroeiverrassing wordt verkregen is een autoregressief model (AR(1)). Er is met een ADF test vastgesteld dat de tijdreeks stationair is.
- De verschillende pre-trained modellen zijn te downloaden via het huggingface transformers Python package te vinden op: https://github.com/huggingface/transformers. Deze downloads horen bij het overzichtsartikel Wolf, T., Chaumond, J., Debut, L., Sanh, V., Delangue, C., Moi, A., … & Rush, A.M. (2020). Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 38-45)
- Een algemeen overzicht van visualisatie- en inspectietechnieken die kunnen helpen bij het ontwerpen van een deep learning model zijn te vinden in Xie, N., Ras, G., van Gerven, M. & Doran, D., 2020 Explainable Deep Learning: A Field Guide fort he Uninitiated, arXiv preprint arXiv:2004.14545.
- Een specifiek tool om BERT, FinBERT en RoBERTA te visualiseren is beschreven in Vig, J. (2019), A Multiscale Visualization of Attention in the Transformer Model. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations (pp. 37-42) en is te vinden op https://github.com/jessevig/bertviz.
- In de historische analyse van het rendement dat hoort bij deze informatiebron wordt het volgende veronderstelt:
- De meest gangbare restricties zijn van toepassing. Te denken valt aan UCITS regels, geen short-selling en limieten op individuele aandelenposities;
- Transactiekosten (one-way) zijn 0,25%;
- Deze informatiebron is alleen voor bedrijven uit de Verenigde Staten beschikbaar;
- Het risico budget is voor deze informatiebron tussen de 0,5% en 1%.
in VBA Journaal door Tjeerd van Cappelle en Robin Niesert